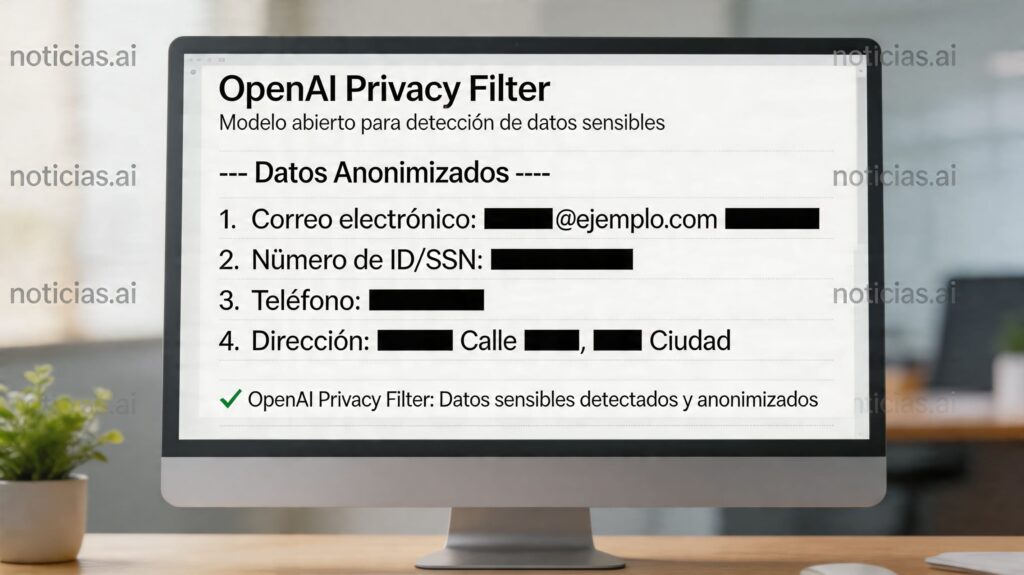
OpenAI has introduced Privacy Filter, a new open-weight model designed to detect and mask Personally Identifiable Information (PII) in text before it’s indexed, recorded, or fed into other AI systems. The company releases it under the Apache 2.0 license and targets high-performance data sanitization workflows, with a clear core idea: allowing companies to run filtering locally without needing to send sensitive text to external services.
This innovation is particularly relevant for the tech sector because it arrives at a time when many organizations are building internal assistants, observability pipelines, RAG systems, and vector databases that process large volumes of text. In all these cases, the same risk arises: if sensitive data, private names, emails, phone numbers, account numbers, or secrets like API keys are not filtered beforehand, they could end up indexed or reused in unintended contexts. OpenAI proposes Privacy Filter as a preliminary layer of protection to mitigate this problem from the outset.
A small, fast model built for production
Unlike a traditional generative LLM, Privacy Filter does not generate text nor answer questions. It is a bi-directional token classification with span decoding model, enabling it to analyze a complete sequence in a single pass and label which segments should be concealed. OpenAI claims that this design improves speed and operational performance compared to heavier token-by-token generation approaches.
In terms of size, it’s in a different league. According to the documentation published by OpenAI on Hugging Face and GitHub, the model has 1.5 billion total parameters and 50 million active parameters, providing a compact architecture that can run “in a web browser or on a laptop.” Additionally, it supports a 128,000 token context window, allowing processing of long documents without constant segmentation. For enterprise environments where latency and cost are as important as privacy, this balance of size and capacity can be more practical than deploying a much larger model for a specific task.
Another practical advantage is that the model does not rely on strict pattern matching. OpenAI explains it is designed to work with unstructured text and context-dependent decisions, which is critical because the same string might be innocuous in one context but highly sensitive in another. This makes Privacy Filter a step above many traditional PII detection tools that rely solely on regexes or format rules.
What it detects and why it’s useful before a RAG system
Privacy Filter operates with a closed taxonomy of eight categories: account_number, private_address, private_email, private_person, private_phone, private_url, private_date, and secret. In practice, this covers everything from private names, addresses, or emails to account numbers, credit cards, passwords, or API keys. The output uses a BIOES scheme, which helps precisely mark the beginning and end of each sensitive span rather than just returning loose matches.
This detail is especially valuable for real-world deployments. In a RAG system, for example, such a tool’s greatest value isn’t just “covering” text but serving as a gatekeeper before ingestion: if it detects a secret or account_number, the organization can block the document or route it for human review before indexing it in a vector database. While not explicitly marketed as such, OpenAI states that the model is intended for training, indexing, logging, and review pipelines, emphasizing its role in data control at early stages.
On performance, OpenAI reports that Privacy Filter achieves a 96% F1 score on the PII-Masking-300k benchmark, with 94.04% precision and 98.04% recall. The company further notes that fine-tuning with small datasets can improve results, especially in domain-specific contexts. These are strong figures, but it’s important to remember that these results are from the vendor’s evaluation, and real-world performance depends on the dataset, language, and deployment conditions.
The key caveat: it’s not total anonymization
This is probably the most critical aspect of this release. Both on its official page and on the Hugging Face entry, OpenAI emphasizes that Privacy Filter is a redaction and minimization tool, but not a comprehensive anonymization solution, not a certification of compliance, and not a security guarantee on its own. The company recommends using it as an additional layer within a privacy by design strategy, rather than relying on it to eliminate all risk.
This warning matters because truly anonymizing data involves more than just removing obvious fields. Many datasets can be re-identified through combinations of dates, locations, work references, or cross-references—even if names and emails are gone. OpenAI doesn’t delve into legal details here, but it’s clear that the model only detects what falls within its trained taxonomy, and organizations may need stricter, broader, or different policies depending on their specific needs.
It’s also worth reiterating that Privacy Filter is not officially presented as a “native Spanish” model. The official Hugging Face page and GitHub repo specify that the primary language is English, with some multilingual robustness tested. OpenAI warns that performance may degrade on non-English texts, non-Latin scripts, or domains outside its training distribution. It might be useful for Spanish, yes, but claiming it as specifically optimized for Spanish would go beyond what the official documentation states.
Overall, the release marks an interesting direction: small, specialized, auditable models that run locally for very specific production problems. They do not replace privacy policies, legal reviews, or secure architecture. But in environments where text flows automatically between agents, logs, and pipelines, having a lightweight, adjustable filter before indexing makes sense as a logical piece of the tech stack.
Frequently Asked Questions
What is OpenAI Privacy Filter and what is it for?
It’s an open token classification model that detects and masks PII in text, intended for data sanitization pipelines, review, indexing, logs, and other workflows where blocking or redactin of PII is needed before the text proceeds further.
Can it run locally without sending data outside?
Yes. OpenAI states it can operate locally and, thanks to its size, even run in a browser or on a laptop, ensuring sensitive text doesn’t leave the device for filtering.
What categories of sensitive data can it detect?
It detects eight span types: account_number, private_address, private_email, private_person, private_phone, private_url, private_date, and secret.
Is it a fully anonymizing tool or a compliance guarantee?
No. OpenAI explicitly states that Privacy Filter is not an anonymization, compliance, or security certification. It should be used as an additional layer within a broader privacy and review strategy.