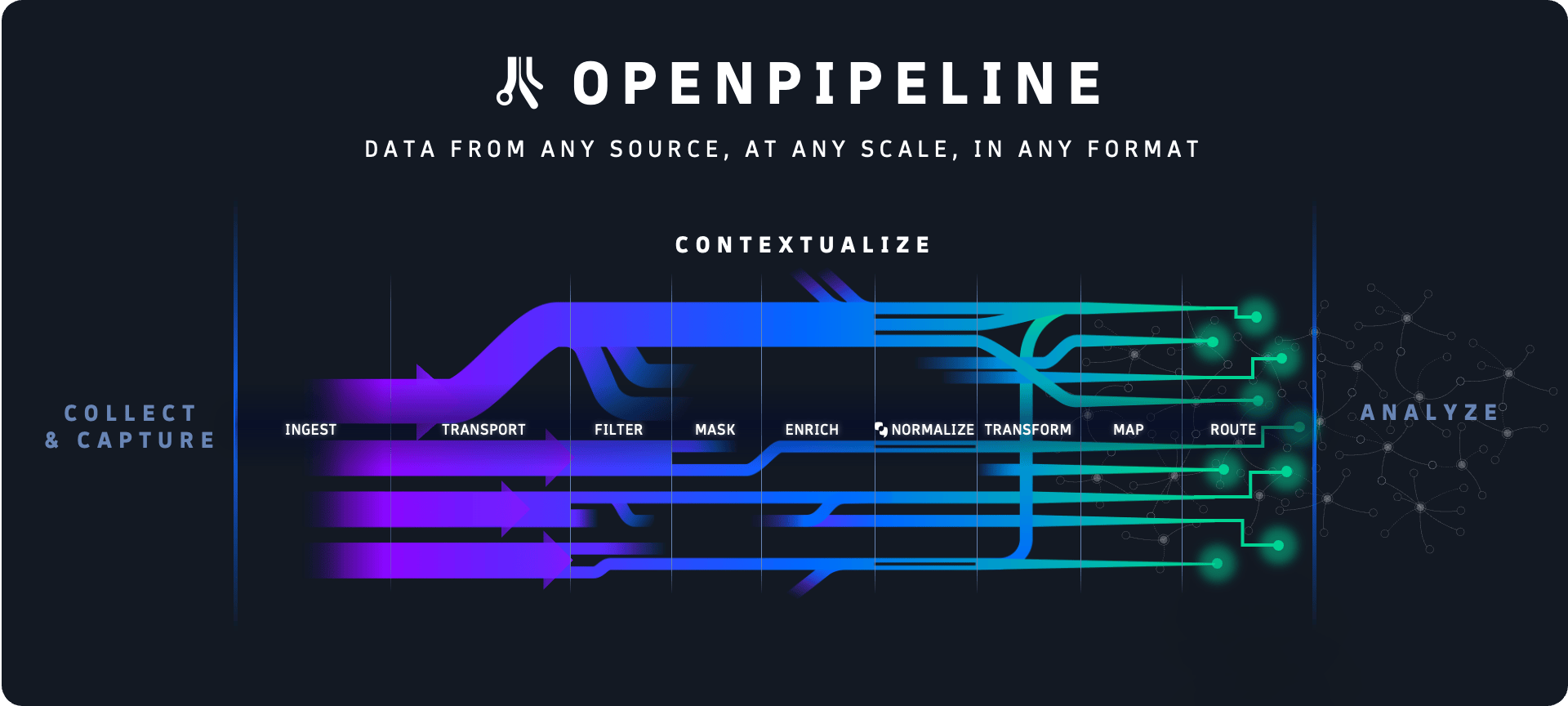
Dynatrace (NYSE: DT), a leader in unified observability and security, has announced the release of OpenPipeline®, a new core technology that provides customers with a single pipeline to manage petabyte-scale data ingestion on the Dynatrace® platform that powers analytics, AI, and automation securely and cost-effectively.
Dynatrace OpenPipeline offers business, development, security, and operations teams full visibility and control over the data they are ingesting into the Dynatrace® platform, while preserving the context of the data and the cloud ecosystems from which they originate. In addition, it evaluates data flows between five and ten times faster than legacy technologies. As a result, organizations can better manage the growing volume and variety of data emanating from their hybrid and multicloud environments and enable more teams to access the AI-driven insights and automations of the Dynatrace platform without the need for additional tools.
“Data is the lifeblood of our business. It contains valuable information and automates processes, freeing our teams from more mechanical tasks,” says Alex Hibbitt, Director of Engineering, SRE, and Fulfillment at albelli-Photobox Group. “However, we face challenges in managing our data pipelines securely and cost-effectively. The addition of OpenPipeline to Dynatrace extends the value of the platform. It allows us to manage data from a wide range of sources alongside real-time data natively collected in Dynatrace, all on a single platform, making it easier for us to make more informed decisions.”
According to Gartner®, “current workloads are generating ever-increasing volumes – hundreds of terabytes and even petabytes each day – of telemetry from various sources. This threatens to overwhelm operators responsible for availability, performance, and security. The cost and complexity associated with managing this data can exceed $10 million annually in large enterprises.”
Creating a unified pipeline to manage this data is a challenge due to the complexity of modern cloud architectures. This difficulty, and the proliferation of monitoring and analysis tools in organizations, can overload budgets. At the same time, companies need to comply with a variety of security and privacy standards, such as GDPR and HIPAA, regarding their data pipelines, analysis, and automations. Despite these challenges, stakeholders in all organizations are seeking more data-driven insights and automation to make better decisions, improve productivity, and reduce costs. Therefore, they need clear visibility and control over the data while managing costs and maximizing the value of their existing data automation and analysis solutions.
Dynatrace OpenPipeline works with other core technologies of the Dynatrace platform, including the Grail™ data lakehouse, the Smartscape® topology, and Davis® hypermodal AI, to address these challenges by delivering the following benefits:
· Petabyte-scale data analysis: Harnesses patent-pending stream processing algorithms to achieve significantly higher data performance at petabyte-scale.
· Unified data ingestion: Enables teams to ingest and enhance routing of observability, security, and business event data – including dedicated Quality of Service (QoS) for business events – from any source and in any format, such as Dynatrace® OneAgent, Dynatrace APIs, and OpenTelemetry, with customizable retention times for individual use cases.
· Real-time data analysis at ingestion: Enables teams to turn unstructured data into structured and actionable formats at the point of ingestion, for example transforming raw data into time series or metrics data and creating business events from log lines.
· Complete data context: Enriches and preserves the context of heterogeneous data points – including metrics, traces, logs, user behavior, business events, vulnerabilities, threats, lifecycle events, and many others – that reflect the diverse parts of the cloud ecosystem where they originated.
· Controls for data privacy and security: Gives users control over the data they analyze, store, or exclude from analysis and includes fully customizable security and privacy controls, such as automatic and role-based PII masking to help meet specific customer needs and regulatory requirements.
· Cost-effective data management: Helps teams avoid duplicate data ingestion and reduces storage needs by transforming data into usable formats – for example, from XML to JSON – and allowing teams to remove unnecessary fields without losing any information, context, or analytical flexibility.
“OpenPipeline is a powerful addition to the Dynatrace platform,” says Bernd Greifeneder, CTO of Dynatrace. “It enriches, converges, and contextualizes heterogeneous data from observability, security, and business, providing unified analytics for this data and the services they represent. Just like with Grail data lakehouse, we have designed OpenPipeline for petabyte-scale analysis. It works with Dynatrace’s hypermodal AI Davis to extract meaningful insights from the data, driving robust analytics and reliable automation. Based on our internal tests, we believe that OpenPipeline, powered by Davis AI, will enable our customers to evaluate data flows between five and ten times faster than legacy technologies. We also believe that the convergence and contextualization of data within Dynatrace facilitates compliance and audits, while empowering more teams within organizations to gain immediate visibility into the performance and security of their digital services.”
Dynatrace OpenPipeline is expected to be available to all Dynatrace SaaS customers within 90 days from this announcement, starting with support for logs, metrics, and business events. Support for other data types will follow.