The startup claims its technology will be up to 10 times faster and more efficient than HBM memory in inference loads, marking a paradigm shift in the relationship between compute and memory.
High Bandwidth Memory (HBM) has become the de facto standard for AI and high-performance computing. Used by giants like NVIDIA, AMD, and Intel, its stacked module design enables bandwidth figures unachievable with conventional memories. But it may not be the ultimate solution for all tasks.
The startup d-Matrix believes it has found a more suitable replacement for one of today’s AI bottlenecks: inference. Their proposal, called 3D Digital In-Memory Compute (3DIMC), promises to be up to 10 times faster and 10 times more efficient than HBM for these workloads.
From training models to deploying them: a different challenge
While HBM is critical for AI model training, which demands massive memory capacity and bandwidth, inference—the phase where trained models process data in real-time—has different needs.
According to d-Matrix, inference is “memory-constrained,” rather than limited by raw computational power (FLOPs). “Models are growing at an incredible rate, and traditional HBM systems are becoming increasingly expensive, energy-intensive, and bandwidth-limited,” explained Sid Sheth, the company’s founder and CEO.
The solution: bring computation closer to the memory and perform operations directly within it.
How 3DIMC works
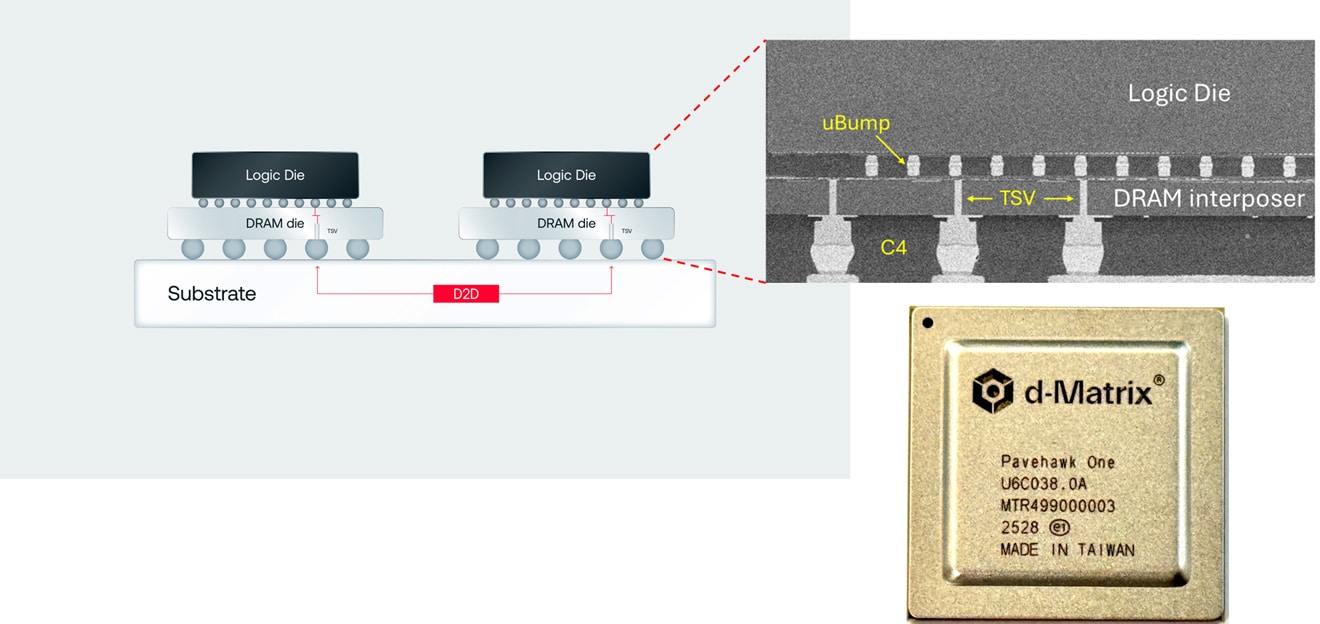
On its Pavehawk chip, currently in lab testing, d-Matrix combines LPDDR5 memories with stacked 3D DIMC chiplets via an interposer. These chiplets contain specialized logic for matrix-vector multiplication, a recurrent operation in transformer-based AI models.
The key is that operations are performed inside the memory itself, drastically reducing latency, increasing bandwidth, and theoretically improving energy efficiency by up to 90% compared to HBM.
The company is already working on the next generation, called Raptor, which aims to definitively surpass HBM in inference workloads.
Economic and strategic implications
HBM currently is a limited and costly resource. Only three manufacturers dominate the market: SK hynix, Samsung, and Micron, and prices are expected to continue rising. SK hynix estimates a 30% annual growth in the HBM market through 2030, adding pressure on data centers and cloud providers that rely on these memories.
In this context, an alternative like 3DIMC appears attractive. A specialized design for inference could lower costs and free large clients—hyperscalers and AI companies—from dependence on just a few suppliers. However, some analysts warn that this specialization might be “too narrow” and risky, especially in a sector already showing signs of overinvestment or a “tech bubble”.
Revolution or niche?
d-Matrix’s approach aligns with a broader trend: designing hardware tailored to each phase of AI’s lifecycle. If training and inference have such different profiles, why force a single memory technology to cover both?
The answer will emerge over the next few years as hyperscalers like Google, Microsoft, and Amazon evaluate the feasibility of adopting a parallel memory ecosystem for inference. For now, d-Matrix aims to prove that its solution is not just a laboratory prototype but a viable market alternative.
Frequently Asked Questions (FAQ)
What sets 3DIMC apart from HBM memory?
While HBM is limited to fast data transfer between memory and processor, 3DIMC performs calculations within the memory itself, reducing data movement and improving efficiency in inference tasks.
Is 3DIMC a direct replacement for HBM?
Not in all cases. It’s geared toward AI inference, not model training, where HBM remains more suitable.
What economic advantages does 3DIMC offer?
It could reduce dependence on major HBM manufacturers and lower infrastructure costs, especially for data centers processing large inference volumes.
When might it become commercially available?
For now, d-Matrix’s Pavehawk is only in laboratory testing. The next chip, Raptor, will seek real-world validation against HBM in the coming years.
via: d-matrix.ai