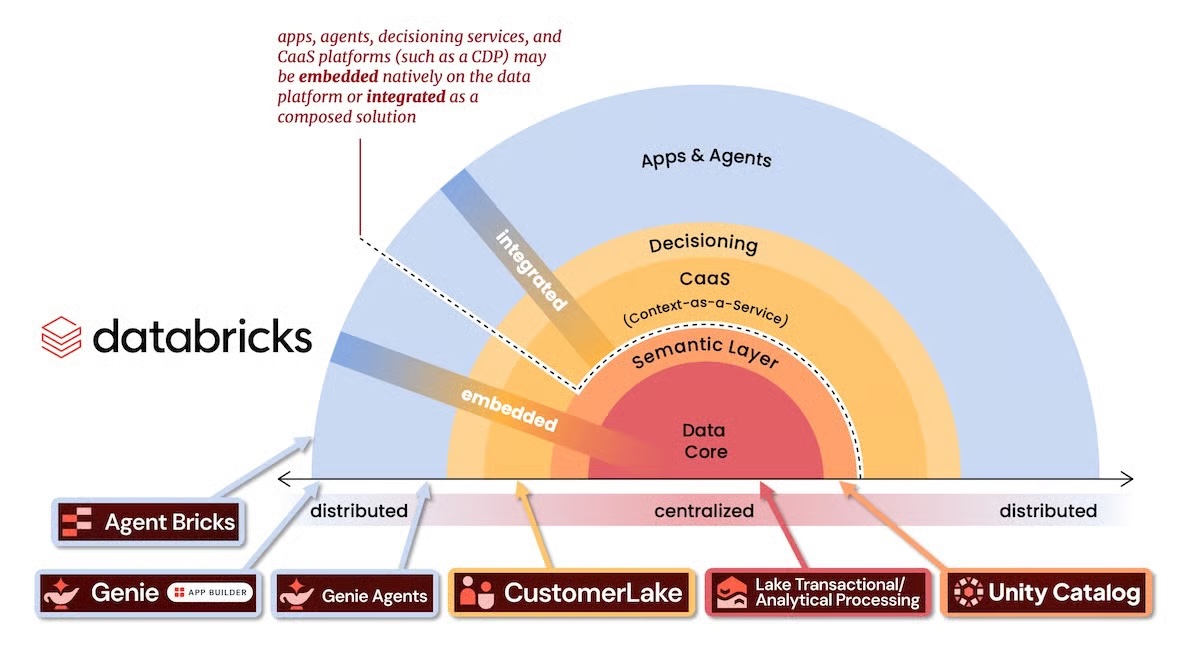
Databricks has just moved a piece that could shift the balance of technology marketing. With CustomerLake, the company has introduced a natively integrated agentic CDP within its lakehouse, featuring Customer 360 capabilities, identity resolution, audience creation, campaign automation, activation, and personalization. The novelty isn’t just adding another marketing tool but placing this layer within the data infrastructure where models, governance, and much of the business context already reside.
For years, the CDP has occupied an intermediate space in the MarTech architecture. It received data from CRM, eCommerce, analytics, support, advertising, and other sources; unified them; generated profiles; and then activated audiences toward external tools. While this model solved many problems, it also created others: data duplication, pipelines, synchronization issues, extra costs, latencies, separate governance rules, and a constant dependence on integrations.
CustomerLake presents a more aggressive thesis: if the data is already in the lakehouse, the CDP doesn’t need to live outside. And if AI agents need to operate on governed, updated, and connected data with models, metrics, and business rules, moving the context to another layer starts to seem like an unnecessary detour.
From traditional CDP to embedded CDP
Databricks defines CustomerLake as an Agentic Customer Data Platform integrated into its platform. According to the company, the product includes Profile Agents to turn raw data into Business-ready Customer 360 profiles, and Campaign Agents to build audiences, recommend next actions, activate channels, and continuously adjust campaigns based on business objectives.
This idea aligns with an evolution the industry has been preparing for years. First, came traditional CDPs that aimed to centralize customer profiles in standalone platforms. Later, composable CDPs and the “zero-copy” approach emerged, driven by the idea of working directly on data warehouses or lakehouses without replicating all data elsewhere. CustomerLake takes this logic further: it not only connects to the data store but is born within it.
| Model | Where the data resides | Main advantage | Common issue |
|---|---|---|---|
| Traditional CDP | In a separate CDP platform | Unifies profiles and audiences for marketing | Data duplication and additional governance layer |
| Composable CDP | On the client’s warehouse or lakehouse | Reduces copies and works directly with data | Still depends on external tools and reverse ETL |
| CustomerLake / Embedded CDP | Inside Databricks Lakehouse | Unites data, agents, models, and governance in one platform | Increases dependency on the data platform |
| Traditional MarTech activation | In marketing and engagement tools | Channel-specific and user-experience focused | Fragmentation and continuous synchronization |
The most delicate point is governance. CustomerLake relies on Unity Catalog, Databricks’ governance layer for data and AI, allowing marketing agents to operate under predefined permissions, controls, and business semantics within the platform. For many organizations, this simplification can be more valuable than a new segmentation feature: fewer duplicate rules, less sensitive data circulating externally, and fewer points where traceability could break.
Infrastructure enters MarTech territory
This move has a clear business interpretation. Databricks is no longer just a provider of data infrastructure but a direct competitor in a layer of application traditionally belonging to MarTech. Scott Brinker, one of the most followed voices in the industry, summarizes it as the moment when infrastructure advances over the application layer. In his analysis, CustomerLake can build Customer 360 profiles, refine segments, resolve identities, and activate personalization in real-time, but its main strength lies in being native to Databricks and operating under Unity Catalog.
This complicates the landscape for standalone CDPs. It doesn’t mean CDPs will disappear—indeed, Databricks could revitalize the category by bringing it into the core of data architecture. However, it forces MarTech providers to explain what value they bring when the data platform already offers profiles, agents, audiences, activation, and governance.
Many companies will still need specialized tools for email, advertising, commerce, customer service, journeys, experimentation, CRM, or loyalty. The market won’t suddenly become a single platform. But the center of gravity might shift. If governed data lives in the lakehouse and agents work there, external applications become channels, interfaces, or experience layers—not necessarily the place for defining customer intelligence.
What are “Infinity Campaigns”
Databricks uses the concept of Infinity Campaigns to describe continuous, agentic campaigns that aren’t limited to a static audience, rule, and send date. The promise is that agents analyze signals from the customer, recommend the next best action, activate experiences across external channels, and adjust decisions based on results.
This responds to a real shift: buyers are also starting to use agents. If a customer delegates part of their research, comparison, or decision-making to automated systems, slow campaign-based marketing—large segments, manual rules—loses effectiveness. The challenge becomes operating within a living context: who the customer is, what they’re doing now, company objectives, previous attempts, and existing constraints.
That context isn’t only from the customer profile. It also includes business rules, inventory, margins, availability, support data, decision history, real-time signals, and product data. That’s why Databricks talks about moving from the “golden record” to the “golden context”: knowing who someone is isn’t enough; understanding what’s happening around them and what the company can do at that moment is essential.
Precedent from Snowflake, BigQuery, and Fabric
The inevitable question is what the other major data platforms will do. Snowflake, Google BigQuery, and Microsoft Fabric already compete to be the data, analytics, and AI backbone of companies. If Databricks demonstrates the ability to embed part of the CDP function, others will face pressure to introduce their own solutions, forge deeper alliances, or develop native activation layers.
Snowflake already has a strong ecosystem around data sharing, data clean rooms, applications, and marketing analytics. Google can connect BigQuery with its advertising business, Gemini models, and cloud tools. Microsoft Fabric has a natural advantage with heavily Microsoft-based organizations leveraging Dynamics, Power Platform, Azure, and Microsoft 365. The trajectory seems clear: data platforms aim to go beyond repositories and evolve into operating systems for enterprise agents.
For marketing teams, this shift demands a serious architectural review. No longer is it enough to ask which CDP has the best interface or most connectors. They need to consider where the master data resides, who governs permissions, how identities are resolved, costs of data movement, activation latency, and whether agents can act with reliable context.
CustomerLake doesn’t eliminate marketing complexity; it shifts it to another layer. It reduces friction in data and governance but requires mature Databricks skills, well-designed models, data quality, clear rules, and real collaboration among marketing, data, technology, and business units.
This launch leaves a hard-to-ignore idea: infrastructure no longer just supports MarTech; it wants a say in decision-making, activation, and personalization. For many brands, this could mean fewer layers and more control. For pure MarTech providers, it’s a warning: their next competitor might not be another CDP but the very data platform they rely on.
Frequently Asked Questions
What is Databricks CustomerLake?
CustomerLake is an agentic CDP integrated within Databricks. It combines Customer 360, identity resolution, segmentation, automation, activation, and personalization on the governed lakehouse built with Unity Catalog.
Does it replace traditional CDPs?
Not necessarily, but it competes with some of their functions. It can reduce the need for a standalone CDP in companies that already centralize data, models, and governance within Databricks.
What’s the difference between a composable CDP and CustomerLake?
A composable CDP operates over data in the warehouse or lakehouse but often remains an external tool. CustomerLake is embedded within Databricks, with integrated agents and governance in the same platform.
What impact could this have on Snowflake, BigQuery, or Fabric?
CustomerLake sets a precedent. Other data providers might be pushed to develop their own CDP capabilities, form deeper integrations, or enter application layers that were once considered MarTech territory.
via: newsletter.chiefmartec and databricks