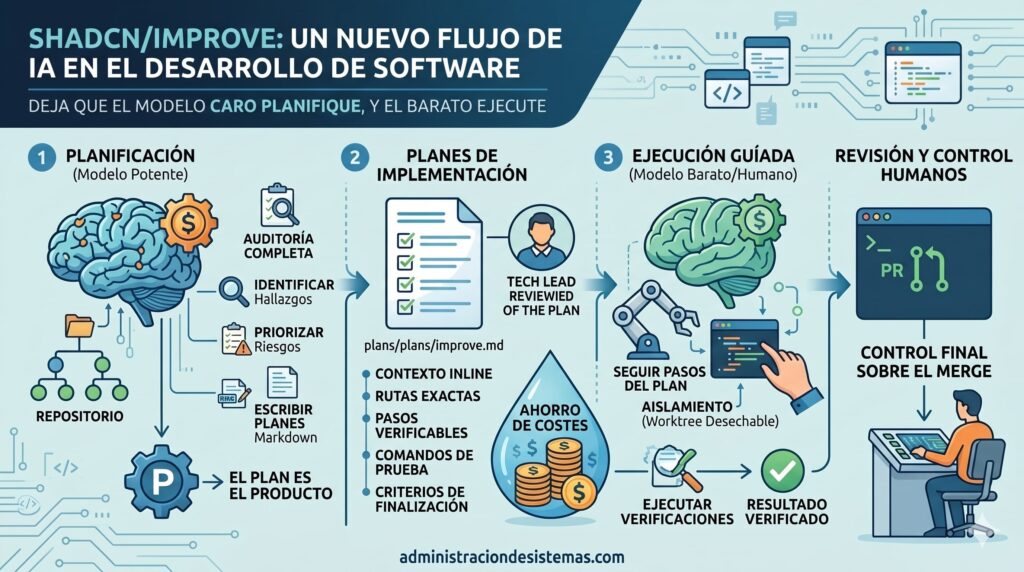
shadcn/improve is one of those small-looking repositories, but with a very powerful underlying idea: not to use the most expensive AI model to write code directly, but to think better. Its proposal is to audit a repository, detect real improvements, prioritize them, and generate detailed technical plans for another, cheaper agent or a human developer to execute later.
This approach comes at a time when development teams are discovering the less glamorous side of AI-assisted programming: cost, noise, and lack of control. An agent can write code, yes, but it can also touch too much, break tests, go out of scope, or spend many tokens on tasks that didn’t require such intelligence. shadcn/improve aims to organize that process with an almost obvious idea: use the most capable model to analyze and plan, and reserve execution for more economical models.
An open, free, and integrable repository
The first virtue of shadcn/improve is that it is open source and licensed under MIT. This means any developer can review it, install it, customize it, learn from its approach, or integrate it into their workflows without depending on a proprietary platform. In a moment where many AI tools for development come as paid SaaS products, this kind of open repository has special value.
Installation is also straightforward: npx skills add shadcn/improve. The project works with agents compatible with the Agent Skills format, and their results are not confined to a proprietary interface. The generated plans are standard Markdown files, saved in a plans/ folder. This allows other agents, developers, technical managers, or internal tools to read and process them.
| Feature | Benefit for the developer |
|---|---|
| Open source repository | Allows review, customization, and understanding |
| MIT License | Facilitates personal, professional, and commercial use |
Installation via npx | Easy onboarding without complex setup |
| Plans in Markdown | Portable, readable, and easy to version control |
| Does not modify code directly | Reduces risks during auditing |
| Compatible with other agents | Flexibility in execution flow |
| Published as issues | Integrates plans into GitHub backlog |

Having the output in Markdown might seem like a minor detail, but it’s one of the best decisions of the project. Instead of creating another closed format, shadcn/improve produces documentation that fits into the existing development culture: pull requests, issues, reviews, checklists, test commands, and traceable decisions.
The expensive model thinks, the cheap one executes
The core idea of the repository is to separate two phases that many tools mix: auditing and execution. The first requires deep understanding. The model should map the repository, understand its architecture, detect conventions, review sensitive areas, and decide what’s worth fixing. That part justifies using a powerful model.
The second phase is different. If the plan is well-written, implementing a specific correction can be a much more mechanical task: changing a file, removing duplication, adding a test, adjusting a migration, running commands, and verifying outputs. Here, a cheaper model or even a junior developer with a clear guide can step in.
| Phase | Who should do it | Reason |
| Reading and mapping the repo | Capable model | Requires overall understanding |
| Detecting real problems | Capable model | Needs technical judgment |
| Prioritizing findings | Capable model or tech lead | Impact versus effort |
| Writing plans | Capable model | Plan quality guides execution |
| Implementing specific steps | Cheaper model or human | More guided and verifiable task |
| Reviewing diffs | Capable or senior human | Final control of scope and quality |
This pattern helps control costs. Instead of letting a costly model implement, test, fail, retry, and consume more tokens, you ask it to focus on what adds the most value: reasoning. The execution is encapsulated in precise instructions.
Self-contained plans to prevent improvisation
One of the most interesting aspects of shadcn/improve is how it writes plans. It doesn’t just say “improve this function’s performance” or “refactor this module.” Each plan must include enough context for an executor who hasn’t seen the original audit to work effectively.
This includes exact file paths, current code snippets, repository conventions, verification commands, expected outputs, completion criteria, and stop conditions. These conditions are key: if the actual code differs from what’s described in the plan, the agent should stop and report rather than improvising.
| Plan element | Why it matters |
| Exact paths | Prevents unnecessary searches |
| Code snippets | Provides context without session dependence |
| Test/lint/build commands | Makes success verifiable |
| Expected outputs | Reduces ambiguity |
| Completion criteria | Defines when a task is done |
| Scope limits | Prevents lateral changes |
| Stop conditions | Prevents small models from inventing solutions |
| Reference commit | Detects if the plan is outdated |
This design is especially useful for smaller models. A less capable agent is more prone to failure when deciding on its own. If it receives a plan with concrete steps, clear boundaries, and verifiable tests, the risk of diverging is much lower.
Audits with repository evidence
shadcn/improve doesn’t aim to generate generic recommendations. Its audit covers areas such as correctness, security, performance, tests, technical debt, dependencies, developer experience, documentation, and project direction. Each finding must be supported by evidence from the code itself, with references to files and lines.
This reduces one common issue with AI in development: false positives. Many models tend to over-report, detect just theoretical risks, or suggest improvements that don’t fit the project. Here, the flow requires review before transforming findings into plans. If something isn’t a real problem, it’s rejected and logged so it won’t reappear in subsequent runs.
| Category | Useful findings examples |
| Correction | Edge cases, logical errors, incomplete validations |
| Security | Risks with evidence in code |
| Performance | Costly algorithms, repeated queries, unnecessary loops |
| Tests | Critical areas without coverage |
| Technical debt | Duplications, degraded abstractions, old TODOs |
| Dependencies | Pending migrations or problematic packages |
| DX (Developer Experience) | Confusing commands, poor environment documentation |
| Documentation | Outdated or incomplete guides |
| Product | Justified suggestions based on repository state |
The results are presented as a prioritized table based on impact, effort, and confidence. The user then chooses which findings to turn into plans. This keeps human control: AI proposes, but the team decides what to add to the backlog.
Helpful for teams, not just for individual tests
While the project can be used for personal repositories, its real value emerges in teams with active codebases. A large monorepo, an application with accumulated debt, or a product with multiple modules can benefit from a tool that consolidates dispersed findings into reviewable plans.
It can also be used before a pull request. The command /improve branch restricts auditing to changes in the current branch, helping identify issues before requesting human review. For teams already using GitHub Issues, the --issues option can publish plans directly as tasks.
| Use case | How shadcn/improve helps |
| Initial repo audit | Detects problems and organizes them |
| Pre-PR review | Analyzes only branch changes |
| Reducing technical debt | Converts issues into actionable plans |
| Security | Focuses review on concrete risks |
| Performance | Looks for bottlenecks with evidence |
| Backlog management | Publishes plans as issues |
| Using cheap agents | Provides clear, verifiable instructions |
| Reviewing existing plans | Critiques and improves previous specifications |
The command /improve reconcile is also valuable. It revisits which plans are still valid, which are blocked, which were fixed elsewhere, and which need updating due to repository changes. In real projects, this function can be just as useful as the initial audit, since the technical backlog evolves quickly.
More process, less “vibe coding”
The popularity of AI-assisted development has created a phase where many programmers ask an agent for wide-ranging changes and accept the results if they seem to work. This can be useful for prototypes but isn’t always suitable for maintained software with tests, security, conventions, and responsibility.
shadcn/improve proposes a more disciplined alternative. It doesn’t eliminate creativity or speed but places these within a process. First, audit. Then, prioritize. Next, plan. Afterwards, execute in an isolated environment. Finally, review and decide whether to integrate.
This aligns with a growing idea in AI development: best results come from workflows where each model has a specific role. The expensive model acts as an architect or lead. The cheaper one as an executor. Tests serve as automatic judges. The developer retains the final decision.
A small repo with a big idea
What’s great about shadcn/improve isn’t that it claims to replace an engineering team. Quite the opposite: it assumes the team exists, that the code matters, that tests matter, and that human control remains essential. Its value is in reducing chaos, turning AI into manageable plans that can be read, discussed, executed, and reviewed.
Being open and free makes the idea even more appealing. Any team can try it without commitment to a new platform, without buying a closed tool, and without overhauling their workflow. If it fits, it integrates. If not, the plans remain in Markdown, and the learning stays in place.
AI for programming doesn’t need more magic. It needs better workflows. shadcn/improve points in that direction with a simple approach: don’t let the most expensive model waste time on minutiae; use it to think, prioritize, and craft good plans. Then, let another execute with clear limits and tests in place.
Frequently Asked Questions
What is shadcn/improve?
It’s an open and free Agent Skill that audits a repository, detects improvements, and generates implementation plans in Markdown for others (agents or humans) to execute.
Why is it interesting that it’s open source?
Because it allows review, customization, and use without depending on a proprietary platform. It’s also released under the MIT license.
Does it implement changes directly in the code?
No. The skill writes plans into the plans/ folder. Execution can be delegated to another agent in an isolated worktree, but merging remains manual.
What problems does it solve compared to other code agents?
It reduces improvisation and costs: uses the most capable model for auditing and planning, and allows cheaper models to carry out well-defined tasks with clear verification steps.